Metrics Service 使用指南
概述
新的 Metrics Service 将 metrics 上报逻辑(包括 tensorboard、wandb、clearml)重构为一个独立的服务,类似 rollout service 的设计。该服务只在 step end 时记录一次,支持批量上报。
架构
┌─────────────────┐ HTTP/REST ┌─────────────────┐
│ Client Code │ ───────────────> │ Metrics Service │
│ (Training/Eval) │ │ (Ray Serve) │
└─────────────────┘ JSON API └────────┬────────┘
│
┌─────────┴─────────┐
│ Metrics Buffer │
└─────────┬─────────┘
│
┌──────────────┼──────────────┐
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ Tensor- │ │ WandB │ │ ClearML │
│ Board │ │ │ │ │
└──────────┘ └──────────┘ └──────────┘代码结构
relax/utils/metrics/
├── __init__.py # 包入口,导出 MetricsClient, get_metrics_client
├── service.py # MetricsService (Ray Serve 部署) + MetricsBuffer
└── client.py # MetricsClient (HTTP 客户端) + get_metrics_client
relax/utils/metrics/
├── metrics_service_adapter.py # MetricsServiceAdapter (向后兼容适配器)
relax/utils/
└── tracking_utils.py # 集成入口 (init_tracking, log, flush_metrics)主要特性
- 独立服务:使用 Ray Serve 部署,与主应用解耦
- 批量上报:只在 step end 时记录一次,减少网络开销
- 向后兼容:保持与现有
tracking_utils.log()相同的接口 - 多后端支持:同时支持 TensorBoard、WandB、ClearML
- 异步处理:metrics 收集和上报分离
配置选项
必需配置
python
args.use_metrics_service = True # 启用 metrics service
# 服务 URL 会自动通过 get_serve_url() 获取,无需手动配置后端配置(与之前相同)
python
# TensorBoard
args.use_tensorboard = True
args.tb_project_name = "my-project"
args.tb_experiment_name = "experiment-1"
# WandB
args.use_wandb = True
args.wandb_project = "my-project"
args.wandb_team = "my-team"
args.wandb_group = "my-group"
# ClearML
args.use_clearml = True
# ClearML 会自动从环境变量读取配置迁移指南
从旧系统迁移
无痛迁移:如果希望保持现有代码不变,只需:
- 在配置中添加
use_metrics_service=True - 在适当位置(如 step end)添加
tracking_utils.flush_metrics(args, step)
- 在配置中添加
逐步迁移:可以同时运行新旧系统,通过配置控制:
- 设置
use_metrics_service=False使用旧系统 - 设置
use_metrics_service=True使用新系统
- 设置
代码示例对比
之前:
python
# 每次需要记录时直接调用
tracking_utils.log(args, metrics, "step")之后(批量模式):
python
# 在训练循环中
for step in range(total_steps):
# ... 训练代码 ...
# 记录 metrics(缓冲,不立即发送)
metrics = {
"step": step,
"train/loss": loss,
"train/accuracy": accuracy,
}
tracking_utils.log(args, metrics, "step")
# 在 step end 时上报所有缓冲的 metrics
tracking_utils.flush_metrics(args, step)API 参考
Metrics Service HTTP API
POST /metrics/log_metric- 记录单个 metricPOST /metrics/log_metrics_batch- 批量记录 metricsPOST /metrics/report_step- 上报指定 step 的所有 metricsGET /metrics/health- 健康检查GET /metrics/query_metrics- 获取已记录的 metricsPOST /metrics/clear_metrics- 清除 metrics
Python Client API
python
class MetricsClient:
def __init__(self, service_url: str = "http://localhost:8000/metrics")
def log_metric(step, metric_name, metric_value, tags=None, immediate=False)
def log_metrics_batch(step, metrics, tags=None, immediate=False)
def report_step(step)
def health_check()
def clear_buffer(step=None)
def get_buffered_metrics_count(step=None)向后兼容 Adapter
python
class MetricsServiceAdapter:
def __init__(args) # 服务 URL 自动通过 get_serve_url() 获取
def log(metrics, step_key="step") # 与 tracking_utils.log 相同接口
def flush()
def direct_log(step, metrics)性能考虑
- 网络延迟:Metrics Service 是独立服务,会有网络往返开销
- 批量优势:只在 step end 上报一次,减少总请求数
- 缓冲机制:Client 端缓冲 metrics,减少网络调用
- 异步处理:Service 内部异步处理上报,不阻塞客户端
故障排除
常见问题
- 服务不可达:检查 Ray Serve 是否正确部署,以及网络连接
- Metrics 未上报:确保调用了
flush_metrics()或report_step() - 后端配置错误:检查 TensorBoard/WandB/ClearML 配置
调试模式
python
# 启用详细日志
import logging
logging.basicConfig(level=logging.DEBUG)
# 检查服务健康
from relax.utils.metrics.client import MetricsClient
from relax.utils.utils import get_serve_url
service_url = get_serve_url(route_prefix="/metrics")
client = MetricsClient(service_url)
health = client.health_check()
print(f"Service health: {health}")示例
完整的示例请参考 relax/entrypoints/deploy_metrics_service.py。
运行示例:
bash
python relax/entrypoints/deploy_metrics_service.pyTimelineTrace
TimelineTrace 用于记录和可视化训练过程中的时间线事件,支持 Chrome Trace Event Format,可在 Chrome 浏览器的 chrome://tracing 中可视化。
配置
bash
--timeline-dump-dir ./timeline_traces # 为空代表关闭,为一个目录代表开启使用示例
python
import time
from relax.utils.metrics.client import MetricsClient
client = MetricsClient()
# 记录事件开始
event_begin = {
"name": "forward_pass",
"ph": "B",
"ts": int(time.time() * 1e6),
"pid": 0,
"tid": 0,
"args": {"step": 100}
}
client.log_metric(step=100, metric_name="timeline", metric_value=[event_begin])
# 执行操作
perform_forward_pass()
# 记录事件结束
event_end = {
"name": "forward_pass",
"ph": "E",
"ts": int(time.time() * 1e6),
"pid": 0,
"tid": 0,
"args": {"step": 100}
}
client.log_metric(step=100, metric_name="timeline", metric_value=[event_end])
# 上报 step,自动导出 timeline
client.report_step(step=100)
# 生成文件: ./timeline_traces/timeline_step_100.json可视化
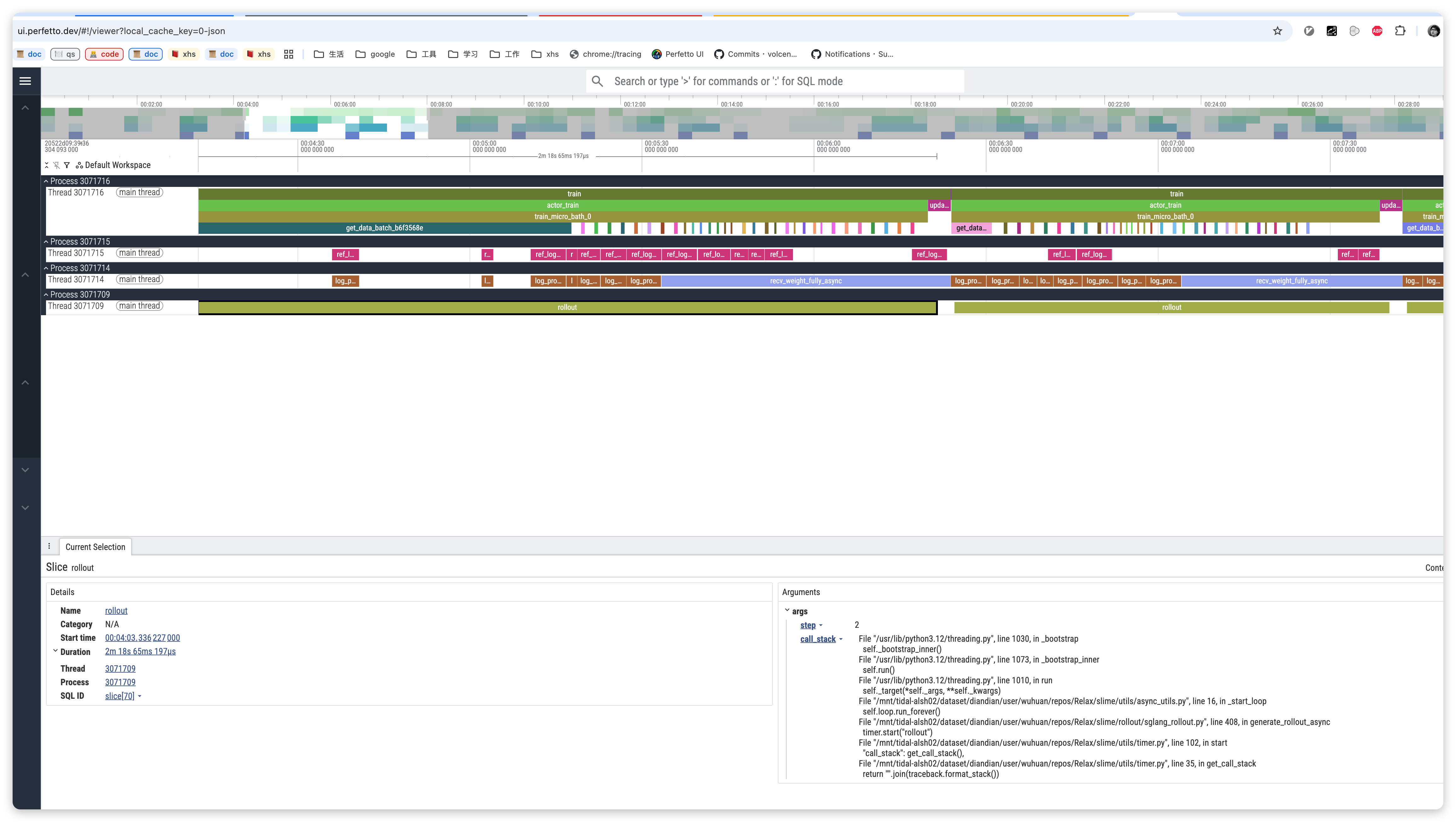
- 打开 Chrome 浏览器
- 访问
chrome://tracing - 点击 "Load" 按钮
- 选择生成的 JSON 文件
总结
新的 Metrics Service 提供了:
- 更好的架构:服务化设计,与主应用解耦
- 性能优化:批量上报,减少网络开销
- 易于维护:集中管理所有 metrics 上报逻辑
- 向后兼容:现有代码无需修改即可迁移
- 扩展性:易于添加新的 metrics 后端